移動機器人視覺
移動機器人視覺 以多顆相機與 AI 為核心,能同時進行深度估計、場景理解與物件辨識,建立更完整的環境感知。
1. 系統概觀
- Sensors: 多顆 RGB-D/立體相機
- Perception: 深度估計、物件偵測、語意分割
- Fusion: 多視角感知融合
- Planning/Action: 視覺驅動的導航與控制
資料流程:/camera + /depth (multi) → perception → /plan → /cmd_vel
2. 主要能力
- 3D 場景重建: 以 nvblox 等工具即時建立體積地圖
- 物件偵測(AI): 透過 YOLOv8 等模型辨識人員/障礙
- 語意分割: 以 UNet 等網路解析像素級語意
- 多感測器融合: 將幾何與 AI 感知整合成一致表示
- 即時感知管線: 多個模組同時執行
3. Demo 與範例程式
-
3.1 nvblox 場景重建
即時重建 3D 環境
-
3.2 多感測器功能
結合雙 3D 相機、物件偵測、語意分割與 3D 建圖目前實作使用 兩顆 3D 相機 作為輸入。
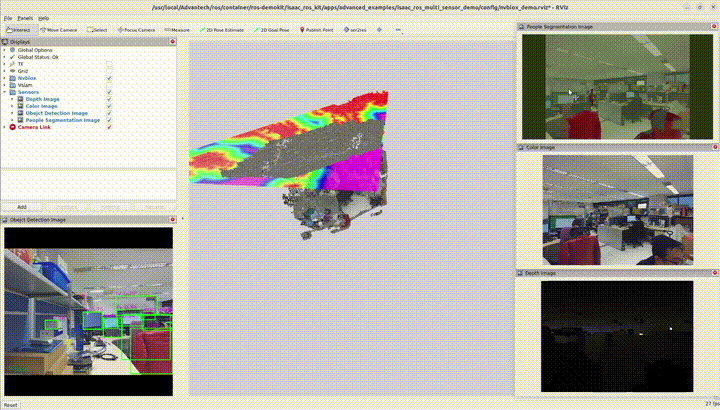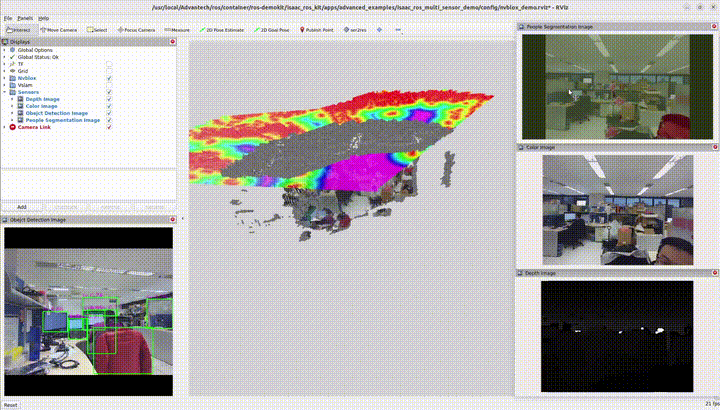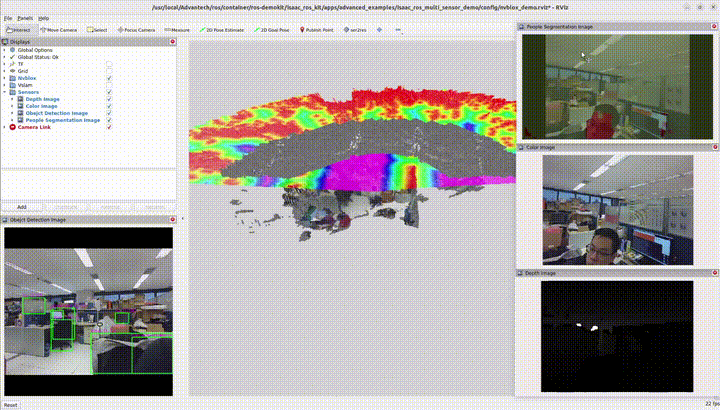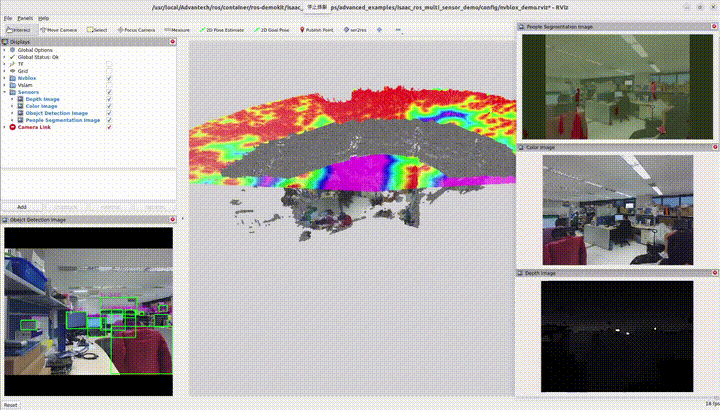
請參考各範例頁面取得安裝、指令與客製化說明。
4. 適用情境
- 智慧服務型機器人
- 自主巡檢系統
- 智慧零售與人群感知
- 結合 AI 與感知的進階研究
5. 注意事項
- 需要高 CPU/GPU 資源
- 系統整合與同步較複雜
- 必須調校延遲與吞吐量
移動機器人視覺 展現「多感測器 + AI」的進化方向,讓機器人更聰明且具適應力。